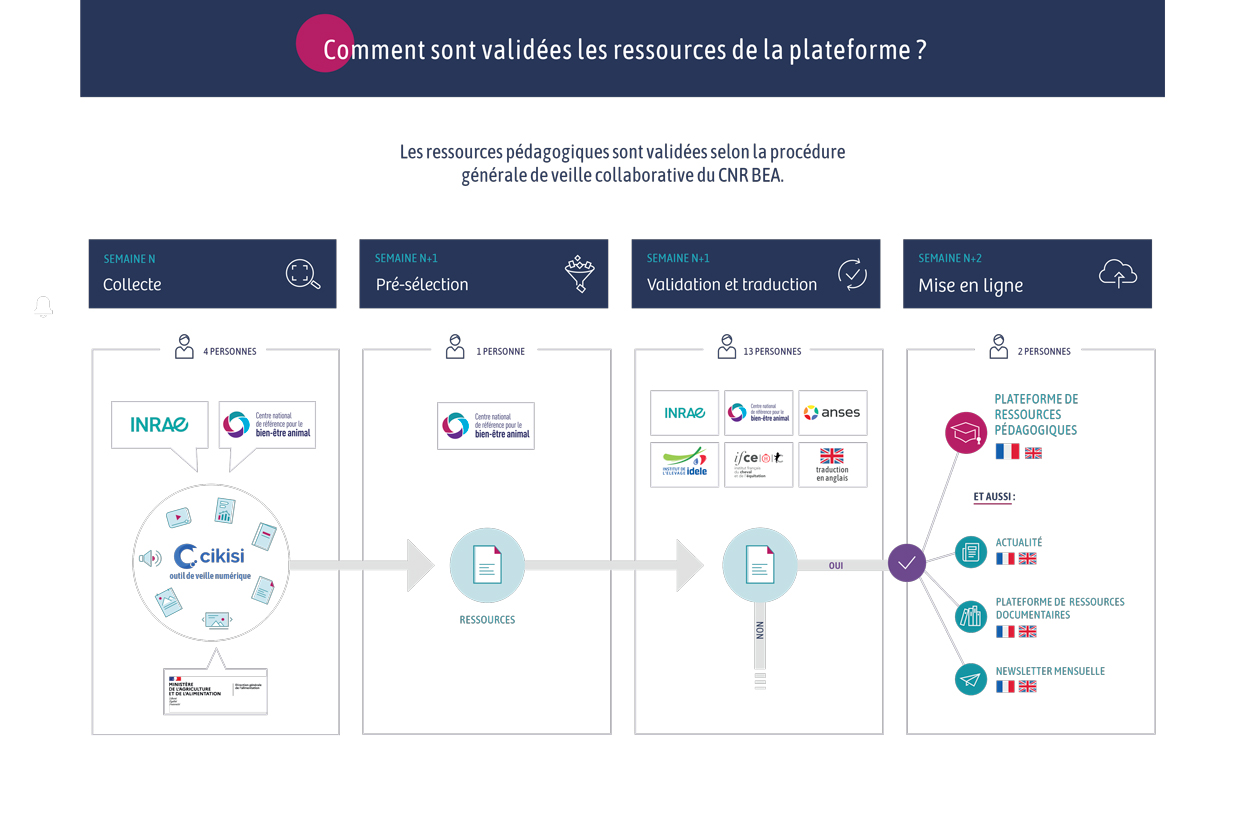
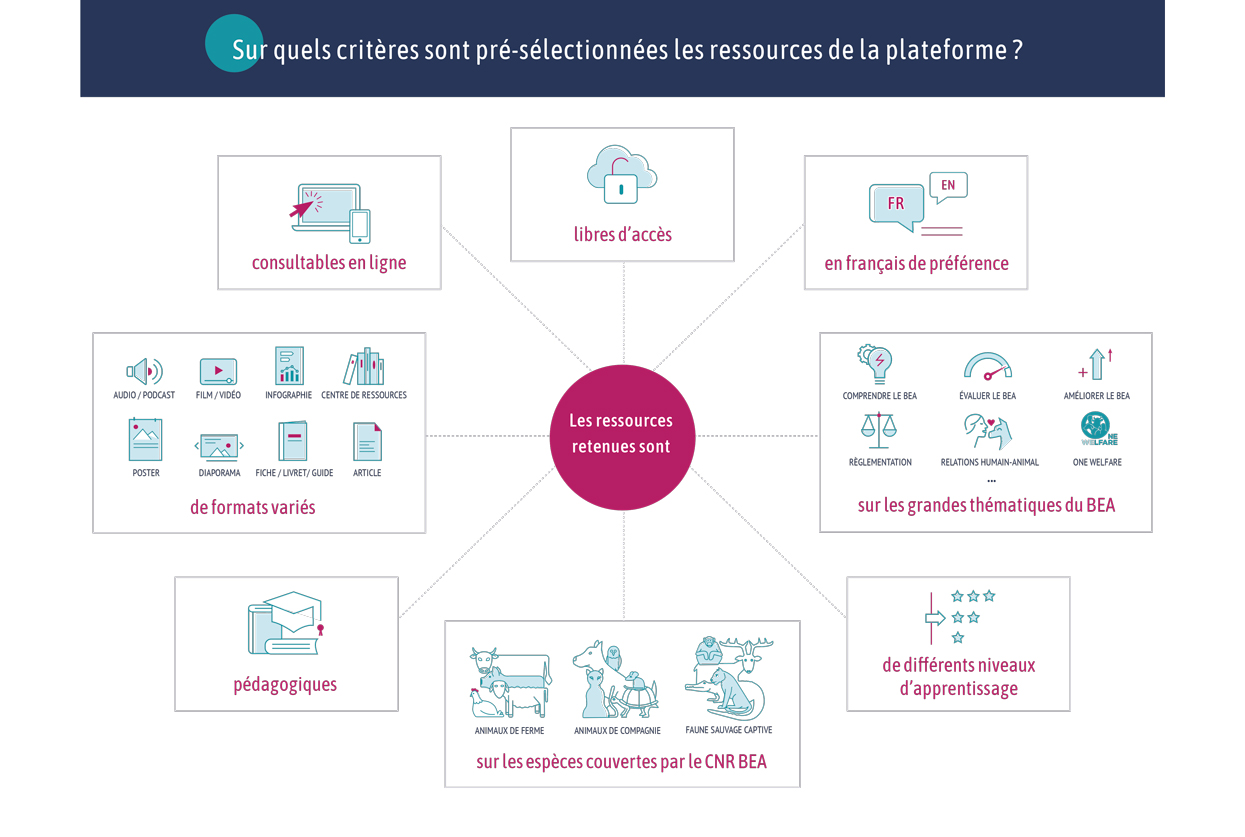
Type de document : article scientifique publié dans Frontiers in Veterinary Science
Auteurs : Rachel Malkani, Sharmini Paramasivam, Sarah Wolfensohn
Résumé en français (traduction) : Validation préliminaire d’un nouvel outil d’évaluation du bien-être des chiens : La grille d’évaluation du bien-être animal
Résumé en anglais (original) : Animal welfare monitoring is a vital part of veterinary medicine and can be challenging due to a range of factors that contribute to the perception of welfare. Tools can be used, however; there are few validated and objective methods available for veterinary and animal welfare professionals to assess and monitor the welfare of dogs over their lifetime. This study aimed to adapt a framework previously validated for other species, The Animal Welfare Assessment Grid (AWAG), for dogs and to host the tool on an accessible, easy to use online platform. Development of the AWAG for dogs involved using the scientific literature to decide which factors were relevant to score welfare in dogs and to also write the factor descriptors. The primary tool was trialed with veterinary professionals to refine and improve the AWAG. Content validity was assessed by subject matter experts by rating the validity of the factors for assessing dog welfare using the item-level content validity index (I-CVI) and scale-level content validity index based on the average method (S-CVI/Ave). Construct validity was evaluated by users of the tool scoring healthy and sick dogs, as well as healthy dogs undergoing neutering procedures. Mann Whitney tests demonstrate that the tool can differentiate between healthy and sick dogs, and healthy and healthy dogs post elective surgery. Test re-test reliability was tested by users conducting multiple assessments on individual dogs under non-changing conditions. Inter-rater reliability was assessed by two users scoring an individual dog at the same time in veterinary referral practice. Repeated measures ANOVA for test re-test and inter-rater reliability both show no statistical difference between scores and that the scores are highly correlated. This study provides evidence that the AWAG for dogs has good content and construct validity, alongside good test re-test and inter-rater reliability.